 |
|
![]()
![]()
The ![]() rule is a generalization of the perceptron
learning algorithm, which tends to minimize the
error. It uses continuous and monotonous functions of activation,
which are thus bijective and derivable, and allow the direction in which
it is necessary to apply the correction, to be assessed.
rule is a generalization of the perceptron
learning algorithm, which tends to minimize the
error. It uses continuous and monotonous functions of activation,
which are thus bijective and derivable, and allow the direction in which
it is necessary to apply the correction, to be assessed.
A gradient method can be used to
minimize the error.
The output S of a neuron using a function of continuous activation is given by:
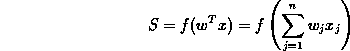 |
The expression of the gradient is given by the derivative of the function of activation, that is:
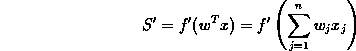 |
The correction carried out to each weight is proportional to the error and to the derivative of the function of activation. The gradient is used to minimize the total error, which for K samples is expressed by:
The correction of the weights using ![]() rule, for a output value S and a desired value D, is defined
as follows:
rule, for a output value S and a desired value D, is defined
as follows:
All the samples are presented to the network, then the total error is calculated. The process is performed until the total error is higher than a fixed threshold.