 |
|
![]()
The final resulting regions are used to determine the samples of the two classes (built up/non-built up areas) on the previous computed similarity image (Figure 63). Both built up and non-built up classes are supposed to appear in the image. This algorithm is made of two steps:
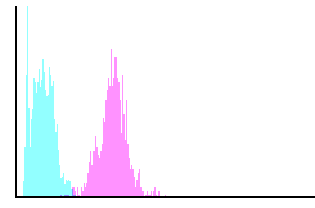
Starting Histogram
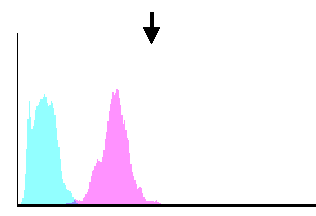
Filtered Histogram
The new threshold value is the intersection between the two filtered histograms' curves:
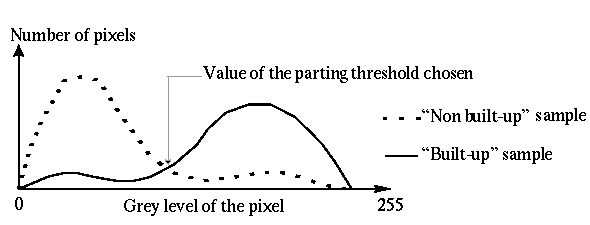
The algorithm ends when the new threshold value has already been computed.
This algorithm is insensitive to wrong segmentation as it only takes into account the best classified regions and it uses filtered histograms to compute the threshold value. If a sample contains some pixels of the other class, these pixels do not influence the choice of the new threshold. With the final samples (in about 4 to 5 iterations), a membership coefficient of a pixel to each of the two classes is defined by using the Bayes' rule.
First, the histograms are modified. For each grey level lower than the
one that corresponds to the maximum of the histogram of the non-built up
sample, the value of the histogram of the non-built up sample is equal
to its maximum. In the same way, for each grey level upper than the one
that corresponds to the maximum of the histogram of the built up sample,
the value of the histogram of the built up sample is equal to its maximum.
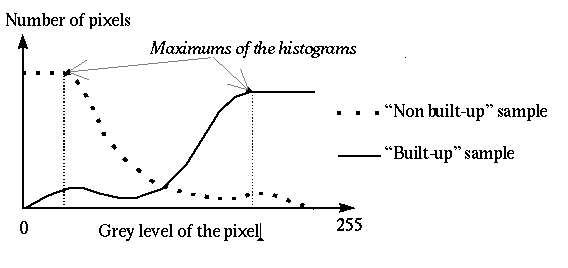
This transformation is made to eliminate the wrong classifications due to the deficiency of knowledge for some grey level values. The transformation can be applied because of the knowledge of the distribution of the two classes (based on the similarity measure of a pixel to a building). Then with these new ``histograms'', the membership coefficient of a pixel to the built up and non built up classes is defined:
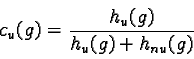 |
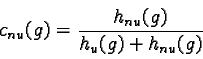 |
hu(g) is the value of the histogram of the built up area sample for the grey level g and hnu(g) is the value of the histogram of the non built up area sample for the grey level g.